

Video
Buongiorno ragazzi, qui Stefano Mini, il fondatore di EdgarBot, oggi andiamo a vedere come funzionano quelle intelligenze artificiali che “imparano” dai vostri dati.
Questo è valido per EdgarBot, certo. Ma anche per tutti quei sistemi di “chatta con il tuo PDF” che si trovano in giro, e qualsiasi altra intelligenza artificiale che impara da un certo documento caricato.
Lo stesso ChatGPT, sul quale si può caricare un documento (come un PDF) e fare domande sul suo contenuto, utilizza questo stesso identico sistema.
Quello che ho visto in giro, è che ci sono tanti strumenti di intelligenza artificiale, sia nel supporto clienti che in altri settori, che la “fanno facile”. Fanno vedere un’implementazione completa del loro programma, rendendo l’AI una soluzione quasi “magica” al problema specifico che cercano di risolvere.
E per quanto l’AI in certi casi sembra veramente magica, ha dei limiti e delle costrizioni delle quali dobbiamo essere a conoscenza, se vogliamo implementarla al meglio e avere aspettative realistiche su quello che riesce a fare.
Noi di EdgarBot, con l’AI, ci lavoriamo tutti i giorni. E io di persona, oltre a EdgarBot, lavoro su diversi progetti AI. Ve lo confesso, la mia opinione sull’AI va da “strumento magico”, a “stupido programmino buggato” più volte al giorno.
Negli anni, ho capito che la differenza tra questi due estremi sta tutta non nella oggettiva capacità dell’AI in sé, ma nel modo in cui organizziamo e strutturiamo le informazioni che ha a disposizione.
Quindi, in questo articolo, voglio parlare del modo in cui le AI “imparano” nuove informazioni e possono aiutarci a ricercare conoscenza all’interno di enormi database di contenuti. Questi concetti possono essere facilmente generalizzati a tutti i tipi di intelligenza artificiale. Anche ChatGPT.
Garbage In, Garbage Out
Il concetto di “Garbage In, Garbage Out”, tradotto in “Spazzatura Dentro, Spazzatura Fuori”, è il più importante quando si pensa all’intelligenza artificiale.
Il termine non deriva dall’AI, ma dal mondo dell’informatica e della programmazione: la qualità dell’output di qualsiasi programma è limitata dalla qualità dell’input.
Se diamo a un programma delle istruzioni sbagliate o di bassa qualità, non possiamo aspettarci altro che un output sbagliato o di bassa qualità. A prescindere dalla qualità del programma stesso.
Questo vale anche, moltiplicato per dieci, nell’intelligenza artificiale.
L’AI ha dei limiti. Ma il limite di gran lunga più comune è quello della qualità dell’input.
Creare un input di qualità per un’AI è un po’ come programmare un software per computer. Richiede tempo, esperienza, fatica.
La “magia” dell’AI sparisce in fretta, quando devi passare giornate intere a strutturare l’input giusto per permettere all’AI di produrre un risultato di qualità.
Un esempio: “chatta con pdf”
Ma facciamo un esempio concreto per capire meglio. Quello di chattare con un PDF: carico un PDF, e posso fare domande la cui risposta è all’interno del PDF stesso. Potrei utilizzare ChatGPT per dimostrare questa capacità, ma visto che voglio farvi vedere come funziona ChatGPT dietro le quinte, andiamo a scrivere un po’ di codice.
Chattare con un PDF è una di quelle funzionalità che sono venute fuori un paio di settimane dopo ChatGPT. Creare un chatbot al quale chiedere il contenuto di un PDF è relativamente semplice, ed è per questo un po’ ovunque. Ma è un ottimo esempio per spiegare il concetto di Garbage In, Garbage Out.
Anche se usiamo le API di GPT invece di ChatGPT, non fatevi spaventare dal codice se non sapete programmare: l’AI che utilizziamo è uguale identica a ChatGPT, ma con un’interfaccia diversa. E spiegherò ogni passo in dettaglio.
In questo esempio chatteremo con il nostro PDF gratuito “Come l’AI cambierà il supporto clienti nel 2024”, che potete trovare a questo link. Per un e-commerce che vuole implementare l’AI nel supporto clienti, questo PDF potrebbe essere il manuale di un prodotto: l’AI deve aiutare il cliente che contatta il supporto a rispondere a una certa domanda, o risolvere un problema la cui soluzione è presente nel manuale.
Questa è un’operazione che un agente umano potrebbe fare, ma a meno di aver memorizzato l’intero manuale di qualsiasi prodotto venduto dall’azienda, richiederebbe parecchio tempo. Quindi è un esempio perfetto.
Passo 1: da PDF a testo
Prima di costruire il nostro chatbot, dobbiamo capire come funziona un chatbot che ci permette di chattare con un PDF.
Il punto dal quale bisogna partire, è che un’AI non è in grado di leggere un pdf. L’unica cosa che può leggere è testo semplice. Quindi il primo passo è di trasformare il nostro PDF in un semplice testo.
Come detto sopra, prendiamo come esempio il PDF “Come l’AI cambierà il supporto clienti nel 2024”. Questo è un PDF che contiene testo, quindi è abbastanza semplice estrarre il puro testo.
Se il PDF contenesse lo scan di un testo, quindi fosse pura immagine, dovremmo usare un sistema chiamato OCR, che è fuori dallo scopo di questo articolo.
Okay, ora abbiamo l’intero contenuto del PDF, che consiste di 19 pagine e 8321 parole. Questo testo può essere usato per chattare con il nostro PDF.
Passo 2: creare un prompt
Ma ora siamo di fronte a un altro problema: come diamo al nostro chatbot le informazioni del PDF?
È tecnicamente possibile insegnare a un’AI nuove informazioni tramite varie tecniche come il fine-tuning o un LoRA. Ma queste tecniche sono estremamente complesse, costose e spesso non offrono un buon risultato finale in un Large Language Model (come GPT).
Per questo la tecnica di gran lunga più utilizzata, e che usiamo anche noi in EdgarBot, è quella del RAG: Retrieval-augmented generation.
RAG significa, in poche parole, creare un prompt per la nostra AI che contiene tutte le informazioni del PDF, e le chiede di rispondere a una certa domanda.
Per “chattare con un PDF” possiamo in sostanza creare un mega-prompt che contiene l’intero PDF, e chiede a GPT di rispondere basandosi sul contesto.
Su ChatGPT si potrebbe fare una cosa del genere:
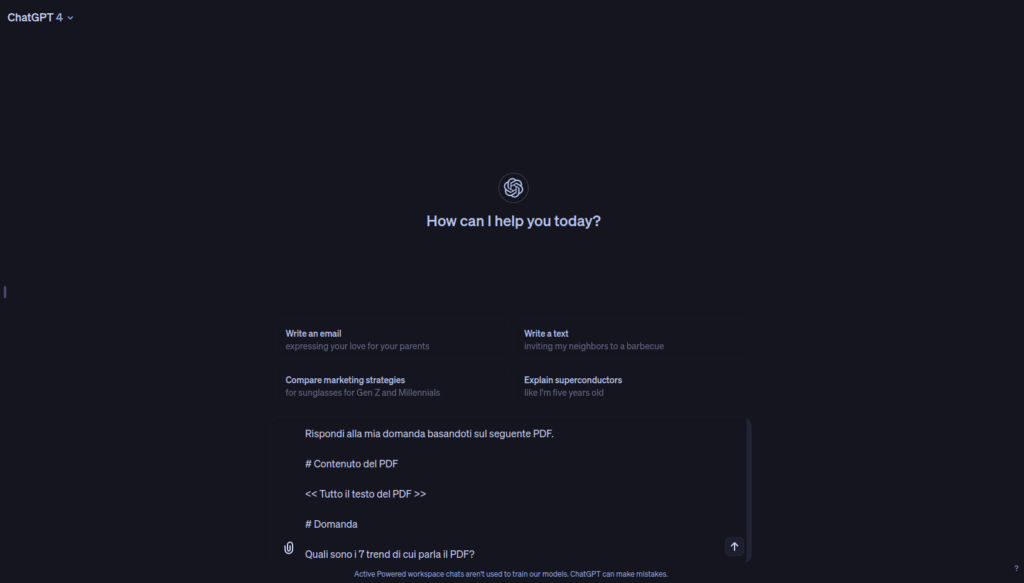
Questo è quello che dice il nostro prompt:
Rispondi alla mia domanda basandoti sul seguente PDF.
Contenuto del PDF
<< Tutto il testo del PDF >>
Domanda
Quali sono i 7 trend di cui parla il PDF?
Qual è il risultato con questa tecnica? Beh, proviamo!
ChatGPT ha dei limiti sulla quantità di testo che possiamo inviare, quindi scriviamo qualche linea di codice per chiamare direttamente le API di OpenAI, utilizzando il modello più recente GPT-4-turbo:
import os
import PyPDF2
from openai import OpenAI
# Estraiamo il testo dal PDF
with open("report.pdf", "rb") as file:
reader = PyPDF2.PdfReader(file)
text = ""
for page_num in range(len(reader.pages)):
page = reader.pages[page_num]
text += page.extract_text()
# La domanda che vogliamo fare al PDF
domanda = "Quali sono i 7 trend di cui parla il PDF?"
# Setup di GPT-4
client = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
# Creiamo il template per il prompt
prompt_template = """Rispondi alla mia domanda basandoti sul seguente PDF.
# Contenuto del PDF
<<TESTO>>
# Domanda
<<DOMANDA>>"""
# Sostituiamo i placeholder con i valori reali
prompt = prompt_template.replace("<<TESTO>>", text).replace("<<DOMANDA>>", domanda)
# Formattiamo i messaggi nel formato che vuole GPT
messages = [
{"role": "user", "content": prompt},
]
# Chiediamo a GPT-4 di rispondere alla domanda
risposta = client.chat.completions.create(model="gpt-4-turbo", messages=messages)
# Stampa la risposta
print(risposta.choices[0].message.content)
Benissimo! Ora lanciamo lo script e vediamo se GPT è in grado di rispondere alla nostra domanda.
Ecco quale risposta mi dà:
I sette trend citati nel PDF sulla rivoluzione dell’AI nel supporto clienti nel 2024 sono i seguenti:
- Comunicazione Personalizzata – L’avvento di IA in grado di fornire risposte personalizzate e specifiche in tempo reale, trasformando il modo in cui le informazioni di supporto vengono consumate dai clienti.
- Modello Zero Attrito – L’eliminazione delle barriere e dei rallentamenti nel supporto clienti, grazie all’IA che rende altamente efficiente anche la comunicazione più costosa, come quella telefonica.
- Approccio Ibrido – L’integrazione di agenti umani con l’IA per gestire richieste che l’IA da sola non può soddisfare, combinando l’efficienza automata con l’intuito umano.
- Raccolta di Dati Strutturati – La raccolta e l’organizzazione efficiente dei dati per alimentare sistemi di IA, facendo sì che possano fornire risposte accurate e pertinenti basate su una vasta base di conoscenze aggiornata e strutturata.
- Migliore Qualità degli Agenti – Con IA che gestiscono questioni standard e ripetitive, gli agenti umani disponibili saranno più qualificati, occupandosi di casi più complessi e specifici, innalzando il livello generale del supporto offerto.
- IA con Ruolo di Supporto – IA che assiste gli agenti umani fornendo loro informazioni cruciale rapide e precise, migliorando la qualità della interazione con i clienti, specialmente in situazioni delicate o complesse.
- Monitoraggio della Soddisfazione del Cliente – L’utilizzo dell’IA per misurare continuamente la soddisfazione del cliente, analizzando le conversazioni e fornendo feedback in tempo reale sugli aspetti da migliorare, riducendo la necessità di sondaggi tradizionali.
Questi trend illustrano un futuro in cui l’IA non solo soppianta alcuni aspetti del supporto clienti ma lavora in simbiosi con gli agenti umani per ottenere un equilibrio ottimale tra efficienza e personalizzazione.
Fantastico! Con questo sistema, posso chattare con il mio PDF e reperire le informazioni che voglio.
Ma ci sono un paio di problemi in questo approccio.
Limite di contesto
Con gpt-4-turbo, rilasciato nella sua versione stabile nell’aprile 2024, possiamo creare prompt molto più lunghi rispetto ai sistemi precedenti: 124.000 token. Un token corrisponde a circa mezza parola in italiano, quindi siamo limitati a un contesto di diciamo 60.000 parole.
Per confronto, il sistema precedente, gpt-4, aveva un contesto di 8000 token (4000 parole).
Questo limite include tutto: il contesto del PDF, la struttura del prompt, la domanda del cliente, l’eventuale conversazione di chat (quindi vari messaggi), e la risposta di GPT. Quindi dobbiamo considerare un margine di sicurezza per inserire tutte queste altre cose. Per questo, abbassiamo a 50.000 parole il limite massimo del PDF, o 100.000 token.
Questo limite è più alto della dimensione del PDF in esempio. Quindi nessun problema. Ma se usiamo questo sistema con un PDF da centinaia di pagine, riceveremo un messaggio di errore.
Prezzo
Il secondo problema è il prezzo. Perché con le API, paghiamo per ogni token che inviamo nel prompt a GPT. Quindi, quanto è costata la nostra domanda precedente?
Per farlo, dobbiamo contare il numero di token del PDF, e moltiplicarli per il costo di 10$ per milione di token.
Possiamo farlo con questo codice:
import tiktoken
import PyPDF2
# Estraiamo il testo dal PDF
with open("report.pdf", "rb") as file:
reader = PyPDF2.PdfReader(file)
text = ""
for page_num in range(len(reader.pages)):
page = reader.pages[page_num]
text += page.extract_text()
# Contiamo i token
encoding = tiktoken.get_encoding("cl100k_base")
num_tokens = len(encoding.encode(text))
print(f"Il PDF contiene {num_tokens} token.")
prezzo_per_token = 10 / 1000000 # 10 dollari per milione di token
prezzo = num_tokens * prezzo_per_token
# Arrotondiamo il prezzo a 2 cifre decimali
prezzo = round(prezzo, 2)
print(f"Il prezzo per analizzare il PDF è di {str(prezzo)} dollari.")
E questo è il risultato:
Il PDF contiene 7910 token. Il prezzo per analizzare il PDF è di 0.08 dollari.
La domanda al nostro PDF ci è costata un totale di 8 centesimi. A questo va aggiunto il costo del resto del prompt e della risposta, ma sono relativamente minori in questo caso, quindi possiamo ignorarli.
8 centesimi può sembrare poco. Ma diciamo che voglio avere più informazioni. Quindi chiedo dettagli per ognuno di questi trend. Faccio altre sette domande, per un totale di 8 richieste. Ogni volta, pago 8 centesimi. Quindi con 8 richieste, pago 64 centesimi per sessione di chat.
Ma io sto gestendo un supporto clienti per e-commerce, e diverse persone al giorno stanno usando questo mio chatbot per “parlare con il PDF”.
Quindi, quando spendo?
Con 10 clienti, sarebbero 6,40$ al giorno. O 192$ al mese!
Non una spesa esorbitante, ma non poco per un chatbot così semplice e limitato.
Risolviamo i problemi di dimensione e prezzo
Possiamo fare di meglio? Certo che sì!
Possiamo spezzettare il nostro PDF in blocchi da, diciamo, 750 caratteri ciascuno. Quando un cliente fa una domanda al nostro chatbot, andiamo a cercare il blocco contenente l’informazione e passiamo solo quella a GPT. Quindi abbiamo solo 750 caratteri, diciamo 300 token di contesto, invece che 7.910.
Et voilà! Abbiamo appena ridotto il costo di ogni richiesta al chatbot di 10 volte. Quindi invece che 192$ al mese, andiamo a spendere solo 7$ circa. Molto meglio.
Implementiamo questo metodo:
from langchain_community.document_loaders.pdf import PyPDFLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
loader = PyPDFLoader("report.pdf")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=750, chunk_overlap=100, separator=".")
docs = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(docs, embeddings)
Okay, questo codice è un po’ più astruso. Ma niente paura: non fa altro che spezzettare il nostro PDF in blocchi da 750 caratteri l’uno, e ci permette di cercarli tramite un database vettoriale.
Database vettoriale?
Non ne parliamo in questo articolo (ne ho già parlato in questo video). Ma in buona sostanza è un sistema per ricercare il testo più simile a una determinata query (o domanda). Quindi se faccio così:
query = "Quali sono le aspettative dei clienti per quanto riguarda la velocità della risposta?"
docs = db.similarity_search(query)
print(docs[0].page_content)
Il sistema andrà a cercare il blocco che contiene l’informazione della query, e lo restituirà. In questo caso, ottengo questo:
Secondo uno studio di Toister Solutions, le aspettative dei clienti stanno cambiando riguardo alla velocità con cui si aspettano una risposta in un ticket di assistenza clienti. Mentre fino a pochi anni fa era consuetudine per le aziende rispondere “dopo un giorno”, gli standard odierni sono diversi: Per qualificarsi come un supporto clienti anche solo “buono”, è necessario rispondere a un’email entro 12 ore, a un messaggio sui social media entro 5 ore e a una chat dal vivo entro 1 minuto. Con l’aiuto dell’IA, questa tendenza si accelererà solo. Poiché l’IA può creare risposte personalizzate e di alta qualità in pochi secondi, man mano che i tuoi concorrenti implementano l’IA i clienti inizieranno ad aspettarsi proprio questo
Questo passaggio è, appunto, un estratto dall’ebook. E contiene esattamente l’informazione necessaria per rispondere alla domanda.
Pare che tutto funzioni! Quindi, possiamo ora andare a creare un prompt per GPT esattamente come prima. Ma invece che passare l’intero PDF, passiamo solo questo piccolo blocco.
import os
from openai import OpenAI
from langchain_community.document_loaders.pdf import PyPDFLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
# Carichiamo il PDF
loader = PyPDFLoader("report.pdf")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=750, chunk_overlap=100, separator=".")
docs = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(docs, embeddings)
# La domanda che vogliamo fare al PDF
domanda = "Quali sono le aspettative dei clienti per quanto riguarda la velocità della risposta?"
# Cerchiamo il documento più simile
docs = db.similarity_search(domanda, k=1)
text = docs[0].page_content
# Setup di GPT-4
client = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
# Creiamo il template per il prompt
prompt_template = """Rispondi alla mia domanda basandoti sul seguente contesto.
# Contesto
<<TESTO>>
# Domanda
<<DOMANDA>>"""
# Sostituiamo i placeholder con i valori reali
prompt = prompt_template.replace("<<TESTO>>", text).replace("<<DOMANDA>>", domanda)
# Formattiamo i messaggi nel formato che vuole GPT
messages = [
{"role": "user", "content": prompt},
]
# Chiediamo a GPT-4 di rispondere alla domanda
risposta = client.chat.completions.create(model="gpt-4-turbo", messages=messages)
# Stampa la risposta
print(risposta.choices[0].message.content)
E la risposta del nostro chatbot è:
Le aspettative dei clienti relative alla velocità delle risposte nei contesti di assistenza clienti sono diventate significativamente più stringenti. I clienti si aspettano ora che le aziende rispondano rapidamente sui vari canali di comunicazione. Per fornire un supporto considerato almeno “buono”, è necessario che le aziende rispondano:
- entro 12 ore a un’email,
- entro 5 ore a un messaggio sui social media,
- entro 1 minuto a una chat dal vivo.
L’introduzione dell’intelligenza artificiale nel supporto clienti sta spingendo queste aspettative ancora più in alto, in quanto l’IA è in grado di generare risposte personalizzate e di alta qualità in pochissimo tempo.
Mitico! Con questo sistema, paghiamo un decimo per ricevere una risposta dal chatbot.
Ma qui sorge un grosso problema…
Il problema del database vettoriale
Ora facciamo al nostro nuovo chatbot la domanda dalla quale siamo partiti:
Quali sono i 7 trend di cui parla il PDF?
Ecco come risponde il nostro chatbot, che ora può vedere solo un blocco. Il blocco è probabilmente differente da quello scelto in precedenza, visto che la domanda è diversa. Ma sarà pur sempre un blocco da 750 caratteri.
Mi spiace, ma non ho accesso diretto al contenuto del PDF menzionato ne al testo completo del report su come l’AI cambierà il supporto clienti nel 2024. Tuttavia, posso ipotizzare alcuni possibili trend basandomi sulle attuali evoluzioni dell’AI nel settore del supporto clienti:
- Automazione migliorata: L’impiego di chatbot e assistenti virtuali capaci di gestire un numero sempre maggiore di richieste in modo autonoma, riducendo il tempo di attesa e aumentando l’efficienza.
- Personalizzazione del servizio: L’IA potrebbe utilizzare i dati dei clienti per offrire un supporto altamente personalizzato, anticipando le esigenze dei clienti e offrendo soluzioni su misura.
- Integrazione omnicanale: L’IA potrebbe permettere un’esperienza di supporto fluida attraverso diversi canali come telefono, email, chat e social media, mantenendo una continuità nel servizio.
- Predizione delle problematiche: Grazie all’apprendimento automatico, l’IA potrebbe identificare modelli ricorrenti nei problemi dei clienti e intervenire preventivamente per risolverli prima che diventino più gravi.
- Miglioramento continuo tramite feedback: L’IA potrebbe analizzare i feedback dei clienti in tempo reale per migliorare continuamente le strategie di servizio e di interazione.
- Supporto proattivo: L’IA potrebbe non solo reagire alle richieste dei clienti, ma anche agire proattivamente per offrire consigli, aggiornamenti e alert personalizzati che migliorano l’esperienza del cliente.
- Formazione e supporto agli agenti umani: Utilizzando l’IA per formare e assistere gli operatori umani, aumentando la loro efficienza e capacità di risoluzione dei problemi.
Questi sono solo esempi speculativi. Per conoscere i trend specifici delineati nel rapporto, ti consiglio di consultare direttamente il documento originale.
Qualcosa non va! GPT dice chiaramente di non avere le informazioni del PDF, e prova ad azzardare una risposta inventata.
Per essere una risposta inventata non è malaccio, ma non è il “chattare con il PDF” che ci aspettavamo.
Quindi questo sistema di spezzettare in blocchi e ricercare solo il blocco con l’informazione necessaria è eccellente se la domanda riguarda qualcosa di specifico, ossia la risposta può essere trovata in un paragrafo o piccolo blocco di testo.
Ma se faccio una domanda che richiede come contesto l’intero documento, non funziona.
Cosa posso fare, quindi?
Posso creare un sistema ibrido: quando arriva una domanda, provo a trovare l’informazione usando i blocchi. Poi uso sempre GPT per identificare se la risposta è all’interno del blocco. Se lo è, genera una risposta. Se non lo è, usa l’intero documento come contesto.
Questo approccio fonde il basso prezzo della divisione in blocchi, con la completezza del poter avere l’intero documento come contesto.
Come gestire documenti multipli
Ma cosa succede quando ho diversi documenti? Allora la cosa si fa più problematica.
Diciamo che il mio chatbot per supporto clienti ha due prodotti simili: due macchine per il caffè Gaggia, ma modelli differenti.
Visto che sono della stessa marca, molte cose saranno simili, ma certi dettagli sono diversi.
In questo caso, non possiamo passare tutti e due i manuali a GPT: il processo non è scalabile con l’aumentare del numero di manuali, e il costo diventa esorbitante.
Né possiamo usare la tecnica dei blocchi: visto che la maggior parte delle informazioni sono simili tra i due prodotti, rischio che il database vettoriale si confonda e reperisca l’informazione del prodotto sbagliato.
Una soluzione a questo problema è di fare due passaggi.
Passaggio 1: selezione categoria
Il primo passaggio è di chiedere alla nostra intelligenza artificiale di selezionare una categoria tra quelle disponibili.
Ad esempio, abbiamo 3 modelli di decespugliatori simili, ognuno con il suo manuale. Al supporto clienti, arriva questa domanda:
Qual è la potenza del decespugliatore a scoppio 5cc?
Il primo passo è chiedere all’AI di scegliere una categoria. Diciamo che abbiamo 3 modelli simili, 5cc, 10cc e 15cc. Possiamo fare una cosa del genere:
from openai import OpenAI
import json
import os
# Inizializiamo il client di OpenAI
client = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
# Creiamo i messaggi nel formato che vuole GPT
messages = [
{
"role": "system",
"content": "Scegli la categoria a cui appartiene la domanda del cliente.",
},
{"role": "user", "content": "Qual è la potenza del decespugliatore a scoppio 5cc?"},
]
# Creiamo la funzione che ci permette di fare la classificazione
functions = [
{
"type": "function",
"function": {
"name": "tag_categoria",
"description": "Classifica la domanda in una delle categorie disponibili.",
"parameters": {
"type": "object",
"properties": {
"categoria": {
"type": "string",
"description": "Il nome del prodotto sul quale il cliente sta chiedendo assistenza.",
"enum": [
"decespugliatore 5cc",
"decespugliatore 10cc",
"decespugliatore 15cc",
],
}
},
"required": ["categoria"],
},
},
}
]
# Chiediamo a GPT-4 di rispondere alla domanda
risposta = client.chat.completions.create(
model="gpt-4-turbo",
messages=messages,
tools=functions,
tool_choice={"type": "function", "function": {"name": "tag_categoria"}},
)
# Carichiamo la risposta e stampiamo la categoria
categoria = json.loads(risposta.choices[0].message.tool_calls[0].function.arguments)
print(categoria["categoria"])
In questa funzione stiamo chiedendo a GPT di scegliere una di tre categorie. E il risultato è:
decespugliatore 5cc
Eureka!
Passo 2: caricare il manuale
Posso ora caricare il manuale del decespugliatore 5cc, e utilizzarlo per rispondere alla domanda del cliente. Posso farlo nello stesso modo descritto sopra, ora che ho la certezza di poter caricare il manuale giusto.
Conclusione
In questo articolo, abbiamo visto che insegnare qualcosa a un’intelligenza artificiale non è banale, e man mano che la complessità di un’applicazione cresce, crescono anche i problemi e le casistiche particolari alle quali bisogna stare attenti.
Questo non è l’unico sistema per insegnare a un’AI nuove informazioni. Ce ne sono altri. Ma quello di questo articolo è il più comune.
Questo è lo stesso sistema che utilizza anche ChatGPT, che nella sua versione Plus permette di caricare PDF o .docx e “chattare” con il proprio documento. Non fa nulla di magico: anche ChatGPT utilizza il RAG, spezzetta in blocchi il documento e cerca quello con la risposta alla domanda.
Questo significa che anche ChatGPT non è in grado di gestire un enorme contesto di informazioni contemporaneamente.
O almeno, per il momento. Le intelligenze artificiali si stanno evolvendo così rapidamente che nel giro di un anno, questo articolo sarà obsoleto. Probabilmente meno.
